

Claude Fable 5 Explained: Anthropic’s First Public “Mythos-Class” AI Model
On June 9, 2026, Anthropic did something it had never done before: it handed the general public a model from its most tightly guarded tier of technology. The model is called Claude Fable 5, and unlike every Claude release before it, this one doesn’t belong to the familiar Opus, Sonnet, or Haiku family. It sits in a class above all of them — a tier Anthropic calls Mythos.
If you’ve spent the last year watching AI models inch forward a percentage point at a time, Fable 5 is a jolt. But it also arrives with a catch that’s just as important as its capabilities: deliberate safety brakes, a premium price tag, and a new data policy. Having spent the better part of a decade building and teaching around these systems, I’ve learned that the launch-day hype rarely matches the day-two reality — so in this post I’ll break it down the way I’d explain it to a room of mixed-experience engineers: first in plain English for anyone, then a practical developer’s guide, and finally a benchmark deep-dive for the data lovers.
What Just Happened?
Imagine a car company that has built an incredibly powerful engine — so powerful that it decided, for safety reasons, only a handful of trained professionals should be allowed to drive it. That’s essentially what Anthropic did back in April 2026 with a model called Claude Mythos Preview. It was extraordinarily capable, especially at finding weaknesses in software, so the company kept it locked behind a limited-access program for cyber-defense partners and a few researchers.
Claude Fable 5 is how that same class of engine finally reaches everyone else — but with safety limiters fitted.
In Anthropic’s own framing, Fable 5 is a Mythos-class model made safe for general use. It’s the same underlying intelligence the company was previously cautious about releasing, wrapped in a layer of safeguards. When you ask it something sensitive — in areas like cybersecurity, biology, or chemistry — it won’t answer with its full power. Instead, it quietly hands your request to Anthropic’s previous flagship, Claude Opus 4.8, which responds more conservatively.
The one-line summary worth remembering: Fable 5 is “Mythos on a leash.” You get the raw intelligence for everyday work, without the unrestricted capabilities that made the original too risky to share.
Why should a non-technical reader care?
Three reasons:
- It’s the most capable AI model the public has ever been able to use. Anthropic says it’s state-of-the-art on nearly every test of AI ability it ran, with its biggest leads on long, complicated tasks — the kind that previously needed a human babysitting every step.
- It hints at where AI is heading. The fact that a company felt the need to split one model into a public “safe” version and a restricted “powerful” version tells you something: the technology is now capable enough that access itself has become a safety question.
- The timing is strategic. Anthropic reportedly filed confidentially for an IPO just days before this launch, after its revenue run-rate reportedly climbed to roughly $47 billion and a funding round valued the company near $965 billion. A more powerful, higher-priced flagship that the public can buy is a logical move heading into the public markets.
The two models, side by side
Anthropic actually launched two closely-related models on the same day. Here’s the simplest way to keep them straight:
| Model | Who can use it | What’s different |
|---|---|---|
| Claude Fable 5 | Everyone (API, paid plans, enterprise) | Mythos-class power, with safety guardrails switched on |
| Claude Mythos 5 | Approved organisations only (via Project Glasswing) | The same model, with some safeguards switched off |
Fun fact on the naming: Fable comes from the Latin fabula (“that which is told”), which echoes the Greek mythos. The names are different because the safeguards are what separate the two — same engine, different keys.
The Developer’s Guide (Specs, Pricing & When to Use It)
Now let’s get practical. If you’re building with Claude — through the API, Claude Code, or an enterprise plan — here’s what you actually need to know.
The core specs
| Feature | Claude Fable 5 |
|---|---|
| API model ID | claude-fable-5 |
| Model class | Mythos-class (one tier above Opus) |
| Context window | 1,000,000 tokens |
| Max output | 128,000 tokens |
| Inputs supported | Text, images, PDFs |
| Knowledge cut-off | January 2026 |
| Launch date | June 9, 2026 |
It’s available today on the Claude API, on claude.ai (Pro, Max, Team, and Enterprise), and across the major clouds — AWS, Google Cloud’s Vertex AI, and Microsoft Foundry.
Pricing: this is a premium tier
Here’s the part that changes your budgeting. Fable 5 costs:
- $10 per million input tokens
- $50 per million output tokens
That’s exactly double Claude Opus 4.8’s $5 / $25 rate card. Unlike the Opus 4.7-to-4.8 jump (which was a free, same-price upgrade), this one comes with a genuine cost decision attached.
A 90% discount applies to input via prompt caching, and US-only inference is available at a 1.1x multiplier.
To make the math concrete, here’s what a single agentic task using 200,000 input tokens and producing 50,000 output tokens costs:
| Model | Input (200K) | Output (50K) | Total per task |
|---|---|---|---|
| Fable 5 | $2.00 | $2.50 | $4.50 |
| Opus 4.8 | $1.00 | $1.25 | $2.25 |
Because output tokens dominate the cost, the gap widens the more verbose and reasoning-heavy your responses get. And remember: frontier models often split one prompt into dozens of sub-agent calls, so a “single” request can quietly fan out. At 2x the per-token price, Fable 5 amplifies that effect — so budget for it and cap it.
A small silver lining: Anthropic and early customers report Fable 5 often finishes tasks in fewer turns and tokens because it’s more efficient. A job that’s 2x the per-token price but uses meaningfully fewer tokens can land closer to Opus than the sticker price suggests — on the right tasks.
The free window you need to plan around
Anthropic is rolling out subscription access in stages, and there’s a deadline worth circling:
| Window | What you get |
|---|---|
| June 9 – 22, 2026 | Fable 5 included free on Pro, Max, Team & seat-based Enterprise plans |
| From June 23, 2026 | Pulled from those plans; usage credits required going forward |
| Later (no firm date) | Anthropic intends to restore it as a standard plan inclusion once capacity allows |
| Always (API) | Billed per token at $10 / $50 throughout |
Practical takeaway: if you want to evaluate Fable 5 cheaply, do it inside the free window before June 22. For anything you’ll run in production at scale, build against the API now and plan your budget around the metered rate, because that’s what persists.
The safety fallback (and why your “Fable” request might return an “Opus” answer)
This is the single most important behavioural detail for developers. Fable 5 ships with safety classifiers — separate AI systems that watch the conversation for misuse. They cover three domains:
- Cybersecurity — exploitation, offensive cyber tasks, and “agentic hacking.”
- Biology & chemistry — currently a deliberately broad net that Anthropic admits is overly cautious, with narrowing planned.
- Distillation — attempts to extract the model’s behaviour to train a competing model.
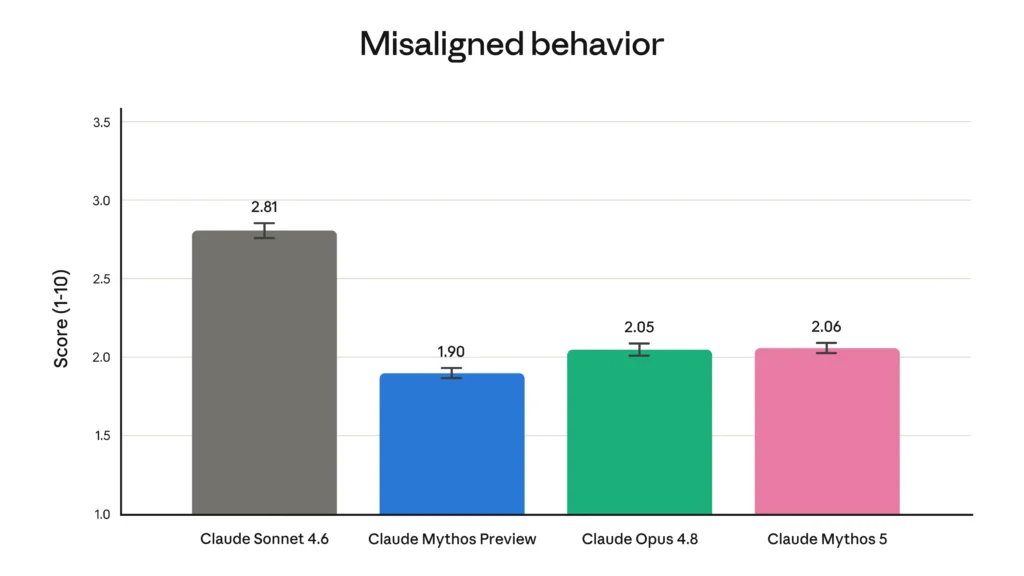
When a classifier fires, Fable 5 doesn’t refuse outright — it routes the request to Claude Opus 4.8, and the user is notified. Anthropic says this happens in under 5% of sessions on average, so for the vast majority of work — coding, analysis, content, research, agentic workflows — the handoff never fires and you get Fable 5’s full strength.
Two things to plan for:
- If your workload lives near security research or life sciences, expect a slice of responses to come from Opus 4.8 — which means you could be paying the Fable premium to receive Opus answers. Test this before you commit.
- On the API, you configure this behaviour explicitly via Anthropic’s new fallback mechanism — it isn’t as automatic as it is inside the Claude apps.
The new 30-day data retention rule
This is the detail most likely to land on your compliance team’s desk. For Fable 5 and Mythos 5, Anthropic now requires 30-day retention on all traffic — even for enterprises that previously held zero-retention agreements.
The company says this data won’t be used to train new models. The stated purpose is narrower: defending against novel attacks and jailbreaks, and reducing false positives in the classifiers. Anthropic says it logs all human access and deletes the data after 30 days in almost all cases.
If zero data retention is a contractual or regulatory requirement for you, that exemption does not apply to Fable 5 — and Opus 4.8 under your existing agreement remains the pragmatic choice for privacy-sensitive workloads.
When to reach for Fable 5 vs. stick with Opus 4.8
Because Fable 5 is exactly double the price, the sane default is a routing strategy: send most work to Opus 4.8, and escalate to Fable 5 only when the task genuinely benefits.
| Reach for Fable 5 when… | Stick with Opus 4.8 when… |
|---|---|
| One-shotting a full app or complex feature | Routine edits, refactors, and bug fixes |
| Long-running, multi-step analytical tasks | Short Q&A, summaries, and chat |
| Highly autonomous agents that self-validate | High-volume, cost-sensitive workloads |
| Hard UI design and game coding | Privacy-sensitive work needing zero retention |
In practice, an LLM gateway that classifies each incoming task and routes by difficulty captures most of Fable 5’s upside while keeping the bill sane.
The Benchmark Deep-Dive (For the Data Lovers)
Anthropic claims Fable 5 is state-of-the-art on nearly all tested capability benchmarks. The numbers largely back that up — but there’s a crucial asterisk you need to understand before you quote any figure.
The headline numbers
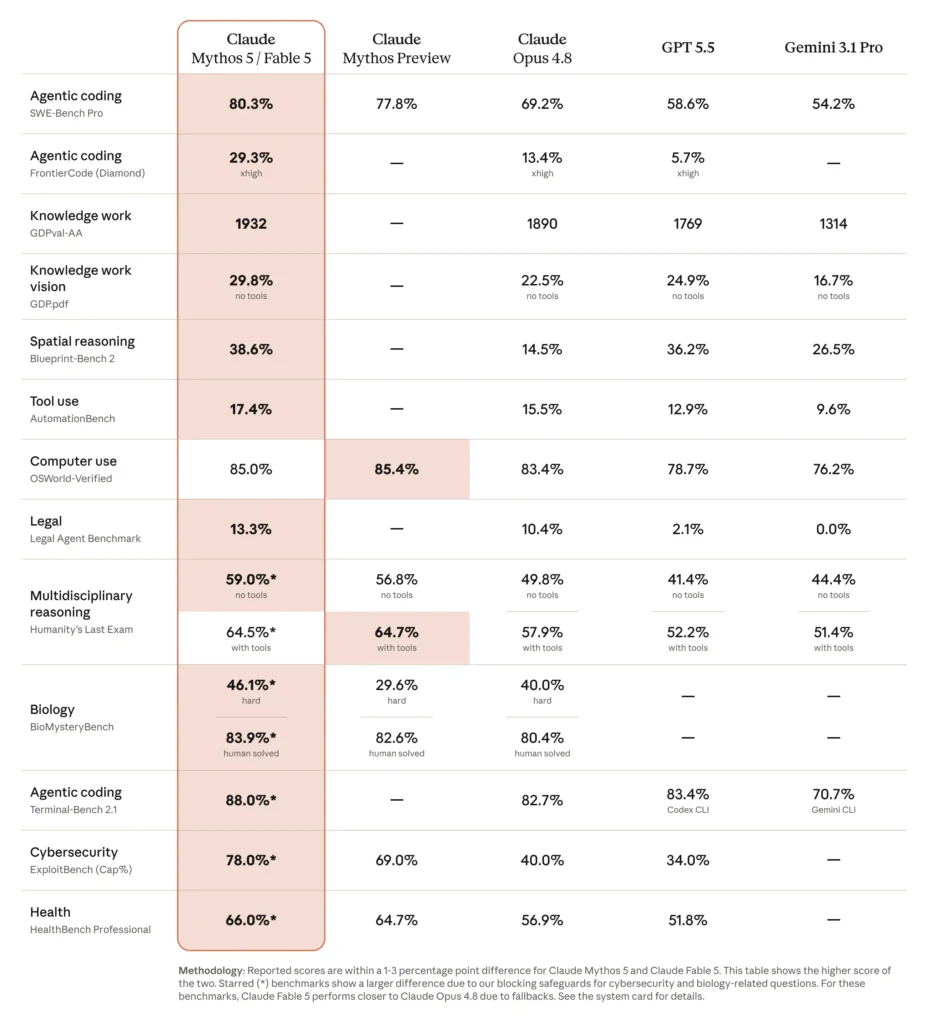
Here’s how Fable 5 stacks up against Opus 4.8 and the leading competitors on the benchmarks Anthropic published:
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro (agentic coding) | 80.3% | 69.2% | 58.6% | 54.2% |
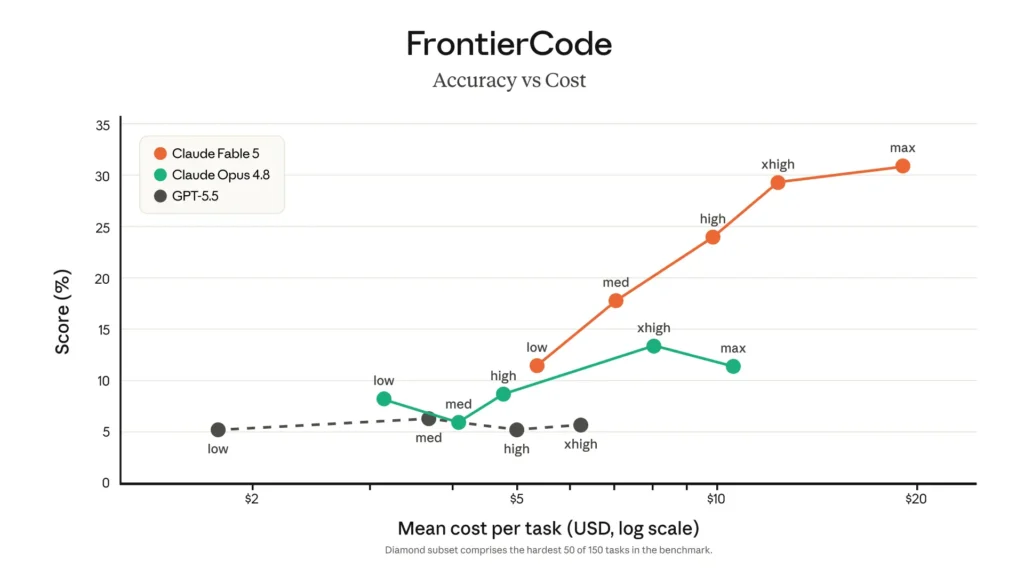
| FrontierCode Diamond (hardest coding) | 29.3% | 13.4% | 5.7% | — |
| GDPval-AA (knowledge work, ELO) | 1932 | 1890 | 1769 | 1314 |
| Blueprint-Bench 2 (spatial reasoning) | 38.6% | 14.5% | 36.2% | 26.5% |
| OSWorld-Verified (computer use) | 85.0% | 83.4% | 78.7% | 76.2% |
| Legal Agent Benchmark | 13.3% | 10.4% | 2.1% | 0.0% |
The standout story is agentic coding. An 11-point lead over Opus 4.8 on SWE-Bench Pro is unusually large — for context, that gap is bigger than the gap between Opus 4.8 and Gemini 3.1 Pro. On the harder FrontierCode Diamond set, Fable 5’s lead is even more dramatic in relative terms (more than double Opus 4.8, and roughly five times GPT-5.5).
The pattern is consistent: the longer and more complex the task, the larger Fable 5’s lead. On shorter, well-scoped tasks, the two models are much closer — which is exactly why Opus 4.8 remains a sensible default for a lot of production traffic.
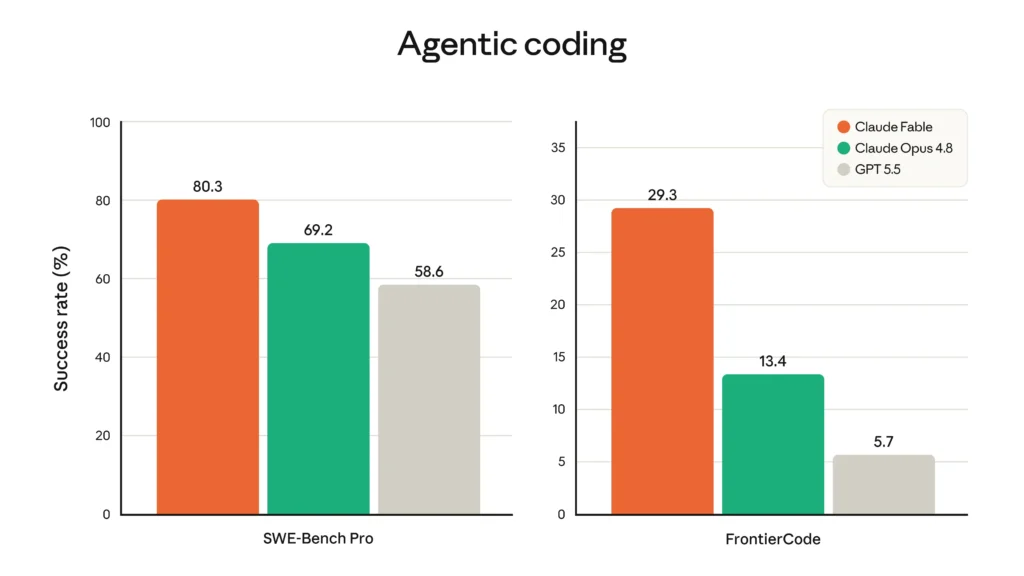
Anthropic also highlights that Fable 5 is more token-efficient than past models — on Cognition’s FrontierCode evaluation, it scores highest among frontier models even at medium effort, meaning it can hit top-tier results without always running at maximum (and maximum cost).
The asterisk you must read before quoting any number
Here’s where most coverage gets it wrong. Anthropic’s official table shows the higher of the Fable 5 and Mythos 5 scores. On most benchmarks the two are within 1–3 percentage points of each other, so this barely matters.
But on starred benchmarks — cybersecurity, biology, and a few others — the displayed figure is Mythos 5’s, not Fable 5’s. Because Fable 5’s safeguards block those exact topics and fall back to Opus 4.8, the Fable 5 you can actually deploy performs closer to Opus 4.8 there.
The clearest example is ExploitBench: the restricted Mythos 5 scores 78.0%, while Opus 4.8 (effectively what Fable 5 falls back to) scores 40.0% — and Anthropic separately reports that Fable 5 in blocking mode made 0% progress on offensive cyber tasks.
The lesson: if you’re evaluating Fable 5 for deployment, treat the starred figures as the ceiling of the restricted model, not the performance you’ll see in production. Don’t benchmark-shop on Mythos numbers for a Fable deployment.
Real-world results (more telling than the charts)
The early third-party signals are arguably more concrete than any benchmark:
- Stripe reported that Fable 5 performed a codebase-wide migration of a 50-million-line Ruby codebase in a single day — work estimated to take a team of engineers more than two months by hand.
- GitLab, which integrated Fable 5 into its Duo Agent, reported measurable improvement in first-shot correctness on complex problems and fewer back-and-forth iterations.
- Crosby Legal, an AI-first law firm, said in blind tests that Fable 5’s contract redlines matched or beat their incumbent model.
- A finance customer reported Fable 5 was the first model to break 90% on its core analytics benchmark — a 10-point jump over Opus.
- One spreadsheet-automation customer found Fable 5 beats Opus 4.8 at every effort level while finishing runs 25–30% faster.
There are playful demos, too: Anthropic showed Fable 5 beating Pokémon FireRed using only raw game screenshots — no maps, no navigation aids, no helper harness that earlier models needed. Given access to file-based memory, it also played the deck-builder Slay the Spire three times better than Opus 4.8.
What the Community Is Saying
The reaction across X, Reddit, and LinkedIn has been a fascinating split between awe and anxiety.
On X, the tone leans enthusiastic among builders. Andrej Karpathy called it a major-version-bump-deserving step change, comparing the leap to Claude 4.5 back in November — while candidly noting the launch-day safeguards felt a little too trigger-happy and would hopefully be tuned over time. Boris Cherny, who leads Claude Code, said it was the best coding model he’d used by a wide margin. Cursor’s CEO said it opened up a class of long-horizon problems that were previously out of reach.
On Reddit, reactions are more divided. A widely-upvoted post argued that Fable 5 feels less like a model launch and more like a “preview of AI inequality” — pointing out that the public version is visibly more restricted than the Mythos version shown to select partners. Others praised it heavily for game development and complex coding, with one r/vibecoding thread sharing a complete game built from a single prompt.
The common thread: genuine excitement about the capability, tempered by frustration over refusals, cost, and what the two-track strategy implies about who gets the “full” model.
Should You Use Claude Fable 5? A Quick Decision Guide
- Large engineering teams: Strongest case. If you work with multi-million-line codebases, complex migrations, or long-running agents, the time savings can easily justify doubling the model cost.
- Startups & indie developers: More delicate. The quality jump is real, but so is the sticker shock and the occasional refusal. If Opus 4.8, GPT-5.5, or Gemini 3.1 Pro already feel “good enough,” route to Fable 5 selectively rather than by default.
- Knowledge workers, researchers, legal pros: Worth it for high-stakes workflows where a single run saves hours — but probably not as your everyday assistant.
- Casual users: Use the free window through June 22 to experiment. After that, it’s more of a power-user feature than a mass-market default.
The Bottom Line
Claude Fable 5 is a genuine milestone — the most capable model the public has ever been able to touch, and the first time a frontier lab has shipped a single model as two products: a safeguarded public version and a gated, more powerful one. Its leads are largest exactly where modern AI work is heading: long, autonomous, multi-step tasks.
But it’s not a magic button. It costs double Opus 4.8, it ships with deliberately conservative guardrails that will occasionally frustrate, it carries a mandatory 30-day data retention policy, and some of its flashiest benchmark numbers belong to a model you can’t actually buy. The smart move isn’t “switch everything to Fable 5” — it’s to route the hardest work to Fable 5 and keep Opus 4.8 as your cost-effective default.
For most teams, that disciplined, task-by-task approach is how you capture Fable 5’s upside without letting the bill spiral. It’s the same advice I give whenever a shiny new model drops: let the work decide the model, not the marketing.
Frequently Asked Questions
What is Claude Fable 5?
Claude Fable 5 is Anthropic’s first publicly available Mythos-class model, launched June 9, 2026. It uses the same underlying model as the restricted Claude Mythos 5, but ships with safeguards that block high-risk queries (cybersecurity, biology, chemistry, distillation) and route them to Claude Opus 4.8 instead.
How much does Claude Fable 5 cost?
$10 per million input tokens and $50 per million output tokens — double the price of Claude Opus 4.8 ($5 / $25). Mythos 5 is priced the same.
How is Fable 5 different from Mythos 5?
They share the same underlying model and the same price. Fable 5 is the public release with guardrails active. Mythos 5 is restricted to approved organisations (via Project Glasswing) with some safeguards lifted.
Is Claude Fable 5 better than GPT-5.5 and Gemini 3.1 Pro?
On the benchmarks Anthropic published, yes — notably +11 points over Opus 4.8 on SWE-Bench Pro, with even larger leads on the hardest coding tasks. The gap narrows on short, routine work.
When does Fable 5 stop being free on Claude plans?
It’s included free on Pro, Max, Team, and seat-based Enterprise plans through June 22, 2026. From June 23, usage requires credits, with Anthropic intending to restore it as a standard inclusion later.
Does using Fable 5 require data retention?
Yes — Anthropic requires 30-day retention on all Fable 5 and Mythos 5 traffic, even for customers with prior zero-retention agreements. The data isn’t used for training, only for safety and abuse detection.
How often does Fable 5 fall back to Opus 4.8?
Rarely — Anthropic’s early data shows the safeguards trigger in under 5% of sessions, so more than 95% of the time you get Fable 5’s full capability.


